
Introduction
In 2006, British mathematician Clive Humby stated that 'data is the new oil', he meant that data, like oil, is not valuable in its raw form. It needs to be processed, refined, and transformed into something valuable. After that, downstream data consumers such as data analysts, data scientists, and machine learning engineers use this valuable data.
Businesses today rely on data to better understand their customers and make data-driven decisions. To learn more about how businesses are using data, check out this article by Bornfight.
Handling small amounts of data can be done manually but when the data volume increases, managing and processing this data becomes challenging. This is where data pipelines come into play.
A data pipeline is a set of methods in which data is collected from single or multiple sources, transformed, and stored in a data repository. While this definition seems simple there are a lot of moving components to consider while building a data pipeline. Should your company aim to develop a reliable data pipeline, the experts at DataHen are at your disposal. Visit our 'Request a Quote' page to get started.
Let's dive into the world of data and uncover the importance and benefits of building robust data pipelines.
Table of Contents
- Why Build Data Pipelines?
- Components of a Data Pipeline
- Benefits of Data Pipelines
- Challenges in Building Pipelines
- Conclusion
Why Build Data Pipelines?
As a company grows, so does the amount and complexity of its data. Data pipelines automate the collection, processing, and analysis of data. Handling this data becomes difficult without a suitable data pipeline in place.
Central Data Hub
Generally, companies have multiple sources of data that are scattered across various databases, cloud storage, on-premise storage, spreadsheets, and more. Consolidating this data into a single repository manually will almost be impossible and the data will mostly be not up to date. By having data pipelines, collecting data from various sources can be scheduled depending on the frequency and can be made easily available for analysis.
Real-time Data Processing
Certain businesses require to have the latest data available for analysis, for example, stock market data. Data pipelines allow for real-time data processing through stream sprocessing which refers to processes of performing operations on the data as it is generated with minimal latency. The advantage of this process is the data is current and can be utilized immediately.
Check out this article by Analytics Insight to learn how companies use real-time analytics to help improve business efficiency.
Scalability and Flexibility
As businesses expand, their need for data also increases. Whether you're dealing with one data source or several, a properly constructed data pipeline ensures smooth and scalable data management.
Data Quality and Integrity
Companies make choices based on the information presented in their reports and dashboards. Therefore, it's essential that this information is both precise and dependable. A variety of tools and systems are available to enhance data quality, reducing the chance of mistakes and inconsistencies.
Cost Efficiency
When a business opts to develop a data pipeline, there are associated expenses. They might need to bring in data engineers or engage firms like DataHen to construct the pipeline on their behalf. Though these expenses might seem significant initially, they often pay off over time. Forward-thinking about data helps companies sidestep expensive oversights and boost efficiency
Components of a Data Pipeline
Just like any other architecture, there are pillars or components that are required to build an end-to-end data pipeline. We will learn about the various components in detail below.
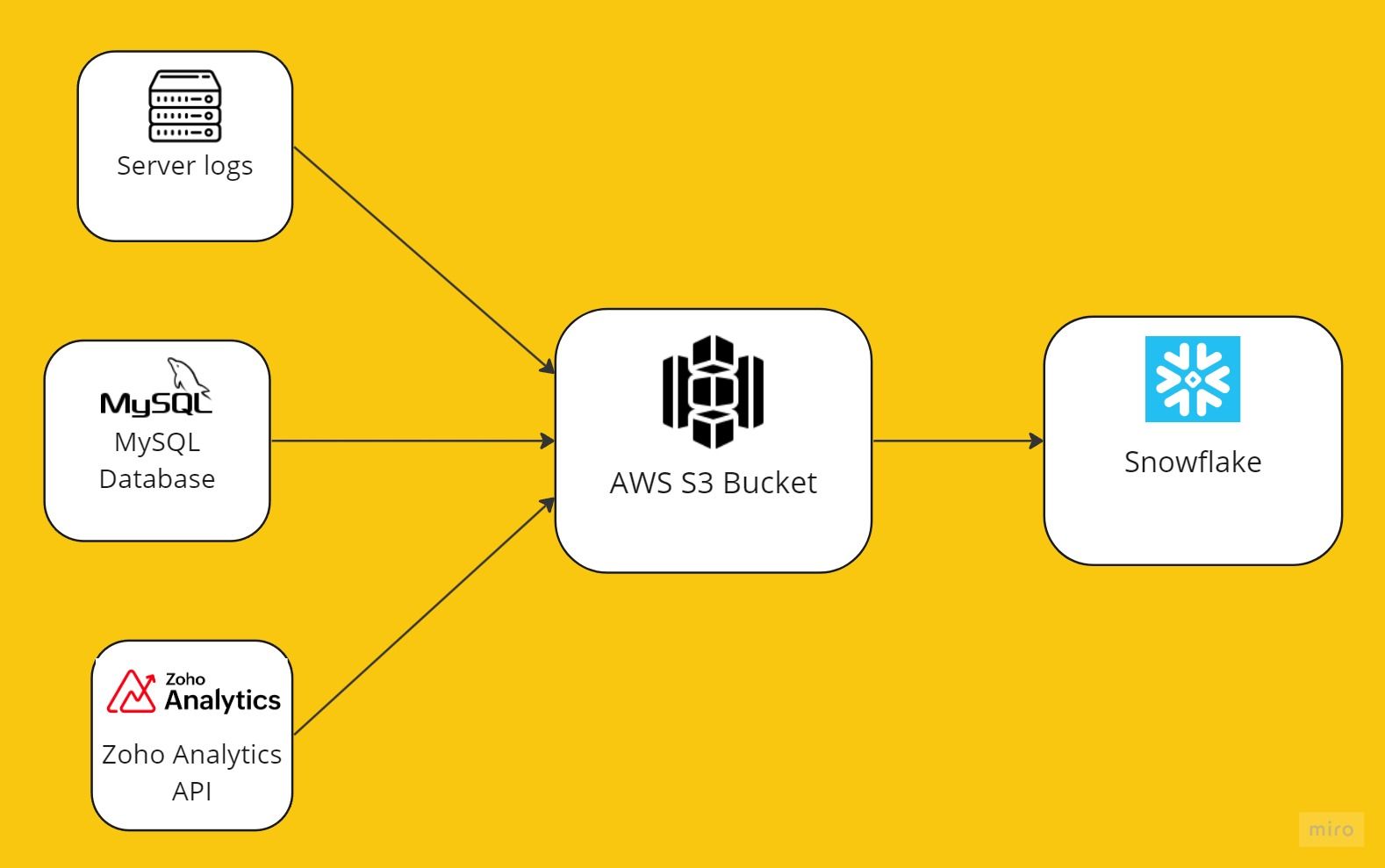
Data Collection
Data acquisition kicks off the data pipeline process. This involves pinpointing one or multiple sources, like sensors, logs, databases, and APIs.
Once we've identified these sources, the next step is data ingestion — the act of importing, processing and storing data from these sources.
Depending on the specific needs, data ingestion comes in two flavors: batch processing and real-time processing. With data in hand, it's essential to run quality checks, ensuring the information is accurate.
There's a suite of tools to aid in this data collection process, including the likes of Apache Kafka, Apache Flume, Logstash, and Amazon Kinesis, among others.
Data Transformation
After data collection, the next step is when we have to clean and refine our raw data into a certain structure. Generally, this involves data cleaning, where you handle missing values and inconsistency in the data.
Once our data is clean, we can try and enrich our data with additional information from other datasets. For example, if you have the town/city data of buyers for your products you could obtain the postal code to get a more granular geographical understanding of the distribution of buyers and run ad campaigns specific to that location.
Another really important step in the data transformation is the normalization of the data to a common format. A simple example can be the date format you have the mm-dd-yy and the dd-mm-yy. There are various tools available such as Apache Spark, Apache Beam, Apache Nifi, and Talend.
Data Storage
Just like with oil once you have the finished product you have to store it before it is shipped to its final destination, the same applies to data. Once we have a clean and standardized dataset we have to store it for later use. Luckily for us, we have various options when it comes to data storage

The most common data storage is databases. You have two kinds, of relational databases which include PostgreSQL, and MySQL and you have non-relational databases such as MongoDB, and Cassandra. You also have data warehouses which are large-scale storage solutions optimized for analysis, examples include, Amazon Redshift, Google BigQuery, and Snowflake. You also have data lakes but it is used to store massive amounts of raw data. Some examples are Amazon S3 and Hadoop HDFS.
Other considerations to make include data retention policy, determining how long data should be held and when it should be achieved or deleted. Choosing a storage solution that scales with your data needs.
Data Visualization and Reporting
Again, just like oil, there are various end-use cases for our data, the most common being dashboards created to track metrics, KPIs, and other important data points. This can be done using tools such as Tableau, Power BI, and Looker to generate reports. In this case, the end users are business analysts or managers and executives who have to make key decisions.
Benefits of Data Pipelines
Enhanced Decision Making
By having data pipelines, businesses are able to make quicker data-driven decisions due to the real-time nature of the data. This can drive up revenue in businesses where time is of the essence. In addition, the automation aspect of a data pipeline ensures the data is accurate and reliable reducing the chance of human error.
Furthermore, by having data from diverse sources that are standardized and complements each other, provides a view of the bigger picture of customer trends and business operations.
Check out this article by GapScout to understand how companies use data to drive decision making.
Cost Efficiency and ROI
Data pipelines are able to streamline the complex task of managing data leading to cutting costs on human computation and errors. As a result, there are more cost savings and optimized utilization of the computation power and storage leading to lower infrastructure costs.
Learn more about how retail can use data to reduce cost with this article from Capgemini.
Furthermore, the in-built redundancy checks of these pipelines help in eliminating duplicate data, making sure that storage is reserved for only unique data.
Streamlined Operational Workflows
Data pipelines stand out for the operational stability they offer. They lay the groundwork for a company's data infrastructure, guaranteeing a seamless data journey and removing potential holdups or isolated pockets.
As companies grow, data pipelines can adapt to meet increasing data demands, eliminating the need for frequent revamps. This efficient handling, paired with a centralized data source, bolsters teamwork and promotes a harmonious work atmosphere.
Improved Data Security and Compliance
As data security becomes ever more critical, data pipelines act like guardians, providing centralized oversight and quickly spotting potential security risks. They have tight access controls in place, ensuring only approved individuals can access sensitive information. A less celebrated but vital feature is their capacity to log detailed audit trails of all data activities, simplifying the process for reviews and audits.
Plus, their programmable nature ensures they remain compliant with ever-evolving regulatory standards, shielding businesses from potential non-compliance penalties.
Challenges in Building Pipelines
Data Integration Complexities
A main hurdle in constructing data pipelines stems from the intricacy of blending multiple data sources. Integrating data from databases, logs, cloud platforms, or third-party APIs can become complex because of varying formats. Many companies still use older systems that weren't crafted for today's data integration, resulting in compatibility challenges. The inconsistent data quality from these sources adds yet another layer of complexity.
While some may provide pristine data, others might present discrepancies. Lastly, a crucial decision that adds to the intricacy is choosing between real-time and batch processing. Balancing or integrating both these processes can complicate the data pipeline architecture.
To learn about more challenges on data integration check this article by HubSpot.
Managing Data Volume and Velocity
The sheer volume and velocity of data can be overwhelming as businesses move deeper into the digital age. Pipelines initially designed for smaller datasets might grapple with scalability as the volume surges. This growth not only challenges the processing capabilities but also has infrastructure implications. Handling larger datasets means incurring more significant infrastructure costs. Beyond volume, velocity also poses challenges.
Ensuring that vast amounts of incoming data are processed and available in real-time or at least near-real-time becomes a challenging task, especially when the influx rate is exceptionally high. Furthermore, determining the optimal storage solutions for these massive datasets, while keeping retrieval processes efficient, becomes a pivotal challenge.
Ensuring Data Privacy
In an era where data privacy has become paramount, ensuring it while building pipelines is a monumental challenge. Regulations such as the GDPR in Europe and the CCPA in California have set stringent data protection standards. Adhering to these, especially when operating globally, becomes a maze of regulatory compliance.
Moreover, it's not just about compliance, businesses need to strike a balance between safeguarding sensitive information through data masking and anonymization while retaining the data's utility. Implementing granular controls to ensure only authorized personnel have access to specific data sets is another complex layer. Finally, one of the pillars of data privacy is the ability to track who accesses the data and when. Setting up robust systems for this monitoring and maintaining clear audit trails for accountability becomes vital, yet challenging.
Conclusion
In the realm of data-driven decision-making, data pipelines play a pivotal role. From collecting raw data to presenting insightful visualizations, each component of a data pipeline ensures that businesses harness the full potential of their data. As we navigate an increasingly digital world, the intricacies of these pipelines will only become more crucial, making understanding and optimizing them an imperative for success.
Looking to implement or improve your data pipeline? At DataHen, we specialize in offering tailored solutions to meet your data needs.
Also, if you're interested in diving deeper into data management challenges, don't miss our article titled "6 Common Data Management Challenges and Possible Solutions".
