

It's Monday morning. You've spent an hour updating your price tracker. 30 tabs, Amazon, Walmart, a few competitors. You do the same Wednesday. Then Friday.
Saturday, you find out a competitor dropped prices 20% Thursday night. They captured the weekend traffic. You missed it entirely.
That's the problem with manual price monitoring.
Spreadsheets only show you what you checked, when you checked it. The market doesn't wait.
Competitor price monitoring is the practice of systematically tracking what rivals charge across channels and marketplaces. Done right, it tells you where the market is moving before it moves past you.
The method is the problem, not the effort. Manual monitoring has a ceiling, and most growing e-commerce businesses hit it faster than they expect.
This post breaks down what competitor price monitoring is, where manual methods break down, and what a scalable approach looks like.
What Is Competitor Price Monitoring?
The Core Definition
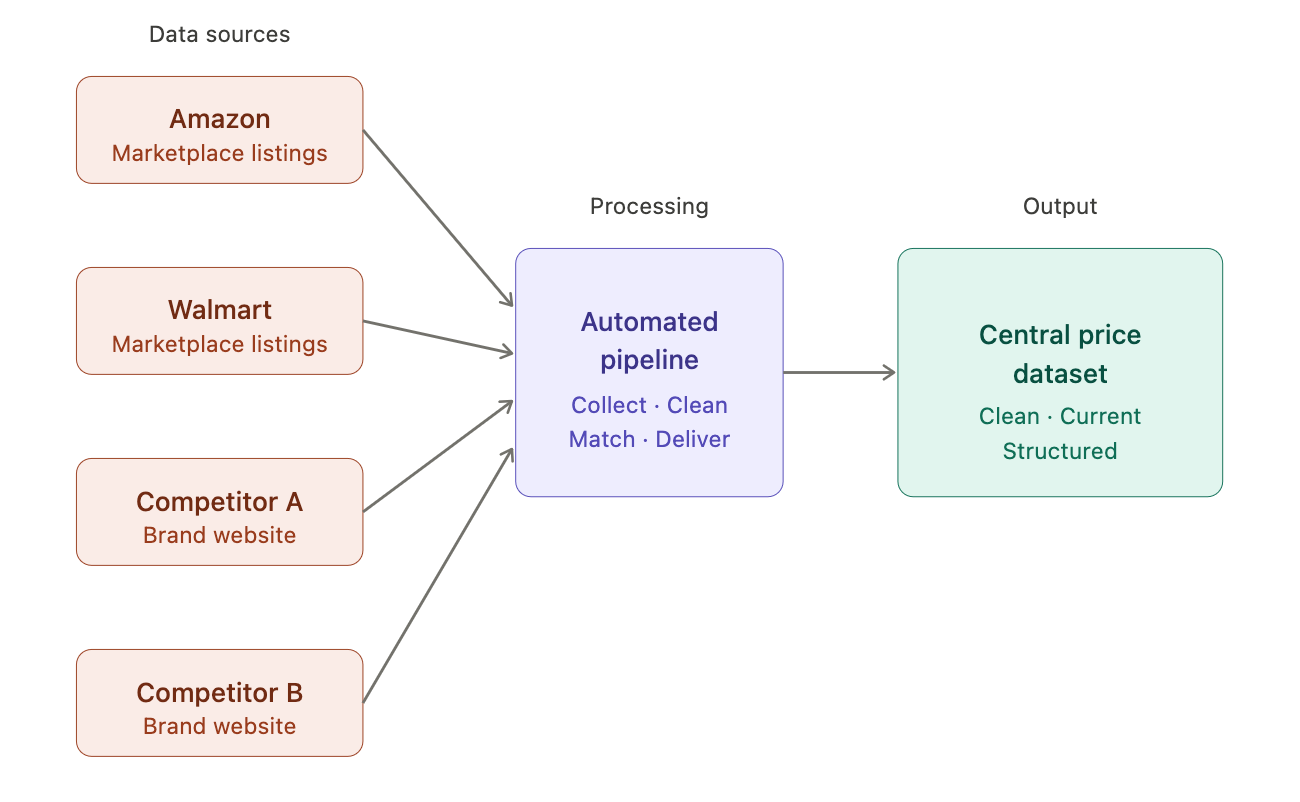
Competitor price monitoring is the process of tracking what your competitors charge for the same or similar products, across their own websites, third-party marketplaces, and any other channel where they're selling.
The key word is systematic. Checking a competitor's site once a week isn't monitoring. Monitoring means continuous, structured data collection across multiple sources, so you always have a current picture of the market, not a snapshot from three days ago.
At small scale, it looks like a spreadsheet and a few bookmarks. At the scale most growing e-commerce businesses actually need, it looks like an automated data collection pipeline pulling prices across dozens of competitors, hundreds of SKUs, and multiple marketplaces, on a schedule you define.
What Data It Actually Captures
Price is the obvious one, but a well-built competitor price monitoring setup captures a lot more than a number next to a product name.
What you're typically tracking:
- Listed price: the base selling price on any given channel
- Sale and promotional pricing: discounts, limited-time offers, bundle deals
- Stock availability: whether a product is in stock, low stock, or out of stock entirely
- Delivery fees and thresholds: free shipping cutoffs, delivery costs that affect the effective price
- Marketplace-specific pricing: the same product often sells at different prices on Amazon vs. a brand's own site vs. Walmart
Each of these data points changes the picture. A competitor might list a product at $49.99, but if they're running free shipping over $40 and you're charging $8.99 for delivery, the real price gap is wider than it looks. You won't catch that from a headline price alone.
Why It's No Longer Optional for E-Commerce Teams
Your customers are already doing this. Research shows that 83% of online shoppers compare prices across multiple sites before making a purchase, and over half check Amazon before buying anywhere else. Price transparency isn't a trend, it's the baseline expectation.
At the same time, the pressure from the other direction is intensifying. A Q4 2025 survey of retail executives found that 53% named rising consumer price sensitivity as one of their top concerns, and that was before accounting for the growing use of AI-powered shopping tools that surface the lowest price automatically.
The businesses that are priced well aren't guessing. They're working from current, structured data. The ones still relying on manual checks are making pricing decisions based on information that's already out of date.
How Does Manual Price Monitoring Work, and Where Does It Break?
The Typical Manual Workflow
Most businesses start the same way. You open a spreadsheet, list your products, and add columns for each competitor. A few times a week, or every day if you're diligent, you visit each competitor's site, find the relevant product, and update the price. Some teams split the work across people. Some use browser bookmarks organized by competitor. Some set calendar reminders to make sure it actually gets done.
It works. For a while.
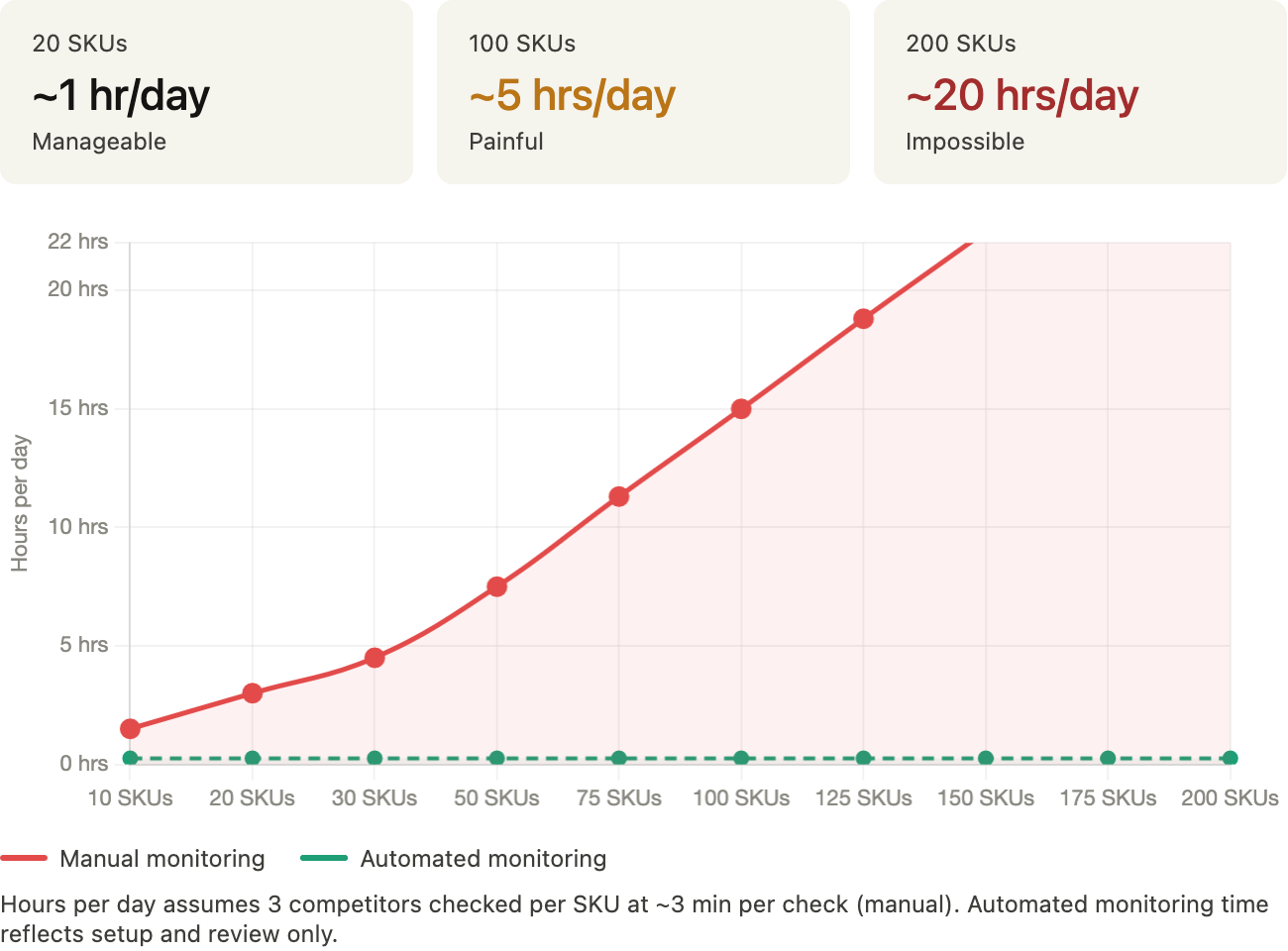
When you have 15 to 20 products and two or three competitors, this process is manageable. It takes 30 to 45 minutes, the data is reasonably fresh, and the decisions you make from it are usually good enough.
The problem is that "good enough" has a hard expiry date.
The Three Failure Points at Scale
Time cost. Manual price checks don't scale linearly, they scale exponentially. Double your SKU count and you've more than doubled the work, because you're now cross-referencing more products across the same number of competitors. Add two more competitors and the whole thing compounds again. The store owner spending 10 to 14 hours a week on price checks isn't doing anything wrong. That's just what manual monitoring costs at 20 to 30 products across three marketplaces. At 200 products, the math stops making sense entirely.
Human error. Manual data entry introduces mistakes at every step. A price gets copied wrong. A tab gets refreshed at the wrong moment and captures a loading error. A sale price gets recorded as the base price. None of these errors are obvious, they sit quietly in the spreadsheet and inform decisions that feel data-backed but aren't. At small scale, one wrong number is a minor inconvenience. At scale, it's a pricing strategy built on bad inputs.
Coverage gaps. This is the failure point that costs the most and shows up the least. Manual monitoring only captures prices at the exact moment someone checks. A competitor who drops prices Thursday night and restores them Sunday afternoon will never appear in a Monday-Wednesday-Friday check cycle. Flash sales, limited-time promotions, and stock-based price changes all happen in the windows between checks. You don't see them, which means you can't respond to them.
What "Scale" Actually Means
Twenty SKUs is manageable. It's tedious, but one focused person can keep it current.
Two hundred SKUs across five competitors on three marketplaces is a different problem category. That's not a bigger version of the same task, it's a task that manual methods were never built to handle.
I've seen teams try to bridge that gap by adding headcount, splitting the work across more people, building more elaborate spreadsheet systems. It buys time, but it doesn't solve the structural problem. More people doing manual checks still miss flash sales. Bigger spreadsheets still contain entry errors. Scheduled check cycles still leave blind spots.
The ceiling on manual monitoring isn't effort, it's method. And for most e-commerce businesses with a growing catalog and real competitors, that ceiling arrives sooner than expected.
What Does Automated Competitor Price Monitoring Look Like?
How Automated Data Collection Replaces the Spreadsheet
Automated competitor price monitoring uses web scraping and data collection pipelines to pull pricing data directly from competitor websites and marketplaces, on a schedule, without anyone opening a browser tab.
Instead of a person visiting a product page and copying a number, a scraper navigates to that page, extracts the relevant data points, and writes them to a structured dataset. It does this across every competitor, every product, and every marketplace you've configured, simultaneously, and as often as you need.
The spreadsheet doesn't disappear entirely. But it stops being where the work happens. It becomes a reporting layer sitting on top of clean, current, automatically collected data. The difference is significant: instead of updating the sheet yourself, you're reading a sheet that updates itself.
For e-commerce teams managing large catalogs, this shift is what makes competitor price monitoring actually usable. You're not spending hours collecting data. You're spending minutes acting on it.

What a Price Monitoring Data Pipeline Actually Does
A data pipeline is what sits between the raw web and the clean, structured dataset your team actually uses. Understanding how it works helps explain why automated monitoring is more reliable than manual methods, not just faster.
At a high level, a price monitoring pipeline does four things:
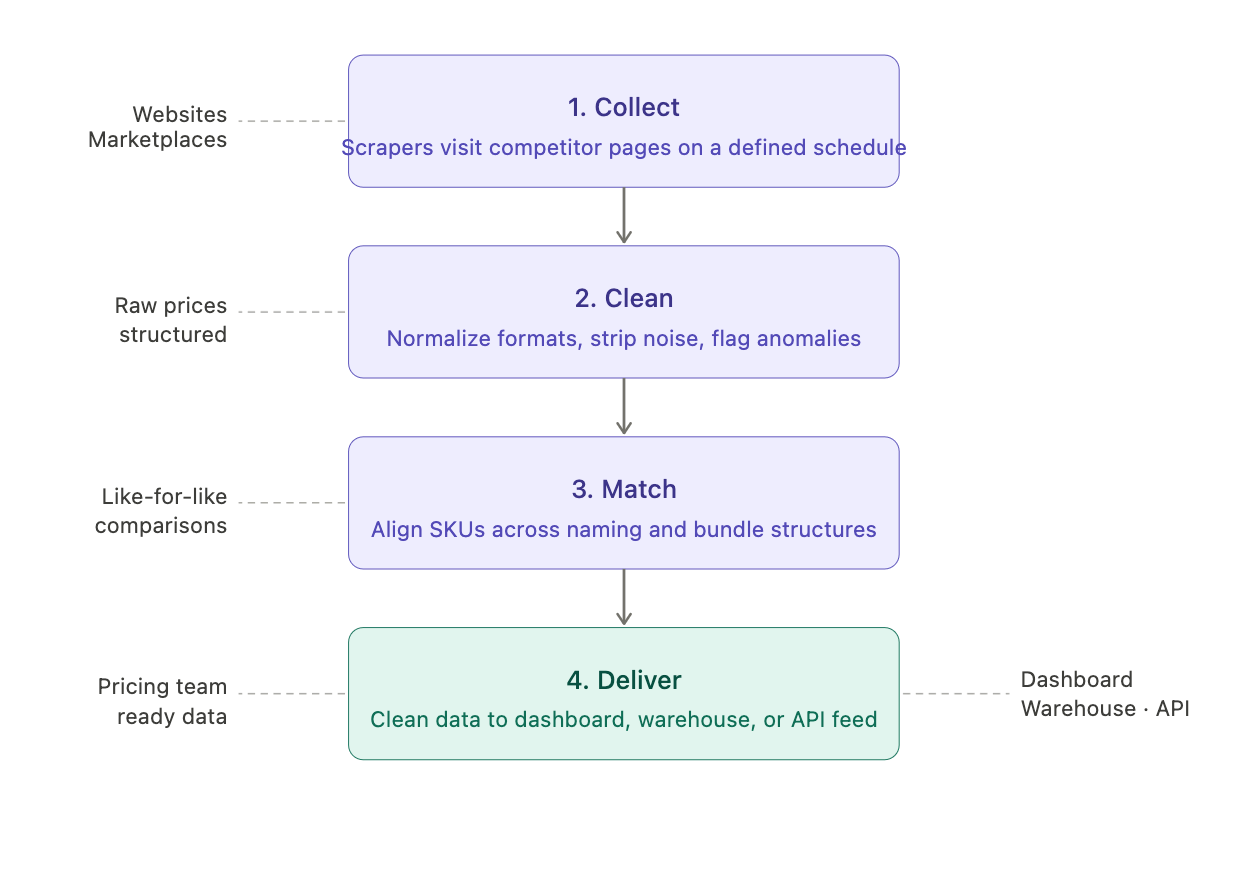
Collects. Scrapers visit competitor pages and marketplaces on a defined schedule, extracting price, stock status, promotional flags, delivery information, and any other configured data points. Modern scrapers handle JavaScript-rendered pages, login-walled content, and sites that actively resist automated collection.
Cleans. Raw scraped data is messy. Prices come back with currency symbols, inconsistent formatting, and occasional extraction errors. The pipeline normalizes all of it, stripping noise, standardizing formats, and flagging anomalies before they reach your dataset. This is the step manual monitoring skips entirely, which is part of why spreadsheet data accumulates errors over time. For a closer look at what this process involves, see our guide on data cleaning in data analysis.
Matches. The same product often appears differently across competitors and marketplaces, different naming conventions, different bundle configurations, different SKU structures. A well-built pipeline handles product matching, so you're always comparing like for like. Without this step, your pricing data is harder to act on than it looks.
Delivers. Clean, matched, structured data gets delivered to wherever your team works, a dashboard, a data warehouse, a pricing tool, or a direct API feed. The pipeline runs on your schedule, so the data is always current when you need it.
Frequency: How Often Should Prices Be Checked?
It depends on your category, but the honest answer is: more often than most manual workflows allow.
For commodity products and high-competition categories, prices can change multiple times in a single day. Major retailers and marketplace sellers adjust pricing algorithmically in response to competitor moves, stock levels, and demand signals. If your check cycle runs once a day, you're already behind.
For most e-commerce businesses, hourly or multiple-times-daily monitoring hits the right balance. You get near-real-time visibility without generating more data than your team can act on.
The specific frequency matters less than the consistency. A reliable automated pipeline running every four hours beats an inconsistent manual process that runs when someone remembers to do it. The goal is a dataset you can trust, one where you know exactly how fresh the data is, every time you look at it.
What Should You Actually Track?
What Products Are Worth Monitoring?
Not every product in your catalog needs the same monitoring frequency, or needs to be monitored at all.
Start with the products where price is actually a deciding factor for your customers. These tend to share a few characteristics: they're available from multiple sellers, they're easy for shoppers to compare side by side, and a price difference of a few dollars visibly affects purchase decisions. Think commodity items, widely distributed brands, and anything that shows up prominently in marketplace search results.
Products with strong differentiation, unique bundles, exclusive variants, proprietary formulations, are less price-sensitive by nature. Customers aren't comparison shopping the same way because there's nothing directly comparable to shop against. You can monitor these, but daily tracking is rarely where the value is.
A practical starting point: identify the 20% of your catalog that drives 80% of your revenue, then cross-reference that with products where you've lost sales to cheaper alternatives. That overlap is your monitoring priority list.
Which Competitors Matter Most?
The competitors worth tracking closely are the ones your customers are actually choosing over you, not every brand in your category.
If you have access to cart abandonment data, lost sale reports, or customer feedback, those tell you directly which competitors are pulling buyers away. If you don't, look at who's consistently appearing in the same search results as your top products. Those are the sellers your customers are comparing you against in real time.
Beyond direct competitors, keep an eye on marketplace sellers, particularly on Amazon and Walmart, where third-party pricing can undercut a brand's own positioning without the brand noticing. A reseller dropping below your MAP price is a different problem than a direct competitor running a promotion, but both affect your conversion rate.
You don't need to track every competitor at the same depth. Tier them. Close competitors with overlapping catalogs get daily or hourly monitoring. Peripheral players get checked less frequently. The goal is signal-to-noise ratio, enough coverage to catch what matters, without generating data you'll never use.
Should You Track Marketplaces Separately from Direct Competitors?
Yes, and treating them the same is one of the more common mistakes in price monitoring setups.
Marketplaces like Amazon and Walmart operate differently from branded e-commerce sites. Prices change more frequently, multiple sellers compete on the same listing, and buy box dynamics mean the "price" a customer sees can shift hour to hour depending on who's winning the featured placement. Monitoring a product's Amazon price once a day gives you a single frame from a movie that's been playing all week.
Direct competitor websites tend to be more stable, price changes are deliberate, promotional schedules are predictable, and the data is cleaner to collect and interpret. These are still worth monitoring closely, but the rhythm is different.
The practical implication: build your monitoring setup to handle both, but don't apply the same frequency and logic to both. Marketplaces need higher-cadence tracking and buy box visibility. Direct competitors need breadth, full catalog coverage, promotional flags, and stock status, more than they need minute-by-minute updates.
How E-Commerce Teams Use Price Data Once They Have It
Dynamic Pricing Decisions
Clean, current competitor pricing data is the input that makes dynamic pricing possible. Without it, you're adjusting prices based on intuition or stale snapshots. With it, you're responding to the market as it actually moves.
In practice, dynamic pricing means setting rules that trigger price adjustments when specific conditions are met. A competitor drops below your price by more than 10% on a high-traffic product, your price adjusts. A competitor goes out of stock, you hold your price or move it up slightly, knowing the pressure has temporarily eased. A flash sale ends, your price resets.
None of this requires a data science team. It requires reliable data arriving on a consistent schedule, and a clear set of rules for what to do when that data changes. The monitoring pipeline provides the first part. Your pricing strategy provides the second.
Research shows that a 1% improvement in pricing generates an average 11.1% increase in operating profit, more than the same improvement in volume or cost reduction. That's not an argument for racing to the bottom on price. It's an argument for pricing precisely, based on what the market is actually doing. For a structured approach to getting that right, see our guide on how to do a competitive pricing analysis.
Promotional Timing and Markdown Strategy
Competitor price data doesn't just tell you what rivals charge, it tells you when they run promotions and how deep those promotions go. That pattern is more useful than a single price point.
If a competitor consistently discounts a product category in the first week of each month, you can either match that timing to stay competitive or run your promotion the week before to capture demand ahead of theirs. If a competitor's promotions are shallow, 5% to 10% off, and yours can go deeper, that's a differentiation opportunity on high-intent shopping days.
Markdown strategy benefits from the same data. Knowing that a competitor has been steadily reducing the price of a product over several weeks is a signal, either they're clearing inventory, repositioning the product, or responding to weak demand. Each scenario has different implications for how you manage your own pricing and stock levels.
This is the layer of insight that manual monitoring almost never surfaces. You'd need weeks of consistent historical data to spot a pattern, and manual checks rarely produce data that's clean or consistent enough to analyze over time.
MAP Compliance Monitoring
For brands that sell through resellers or distribution partners, minimum advertised price compliance is a persistent operational problem. Resellers cutting below MAP undermine brand positioning, create channel conflict, and put compliant partners at a disadvantage.
Manually policing MAP across dozens of resellers and multiple marketplaces isn't realistic. Automated price monitoring solves this by flagging violations as they happen, giving your team the specific seller, the specific product, and the specific price, without anyone having to go looking for it.
The same setup that tracks competitor pricing can track reseller pricing. The data collection logic is identical. The only difference is what you do with the output, in this case, enforcement rather than strategy.
For brands operating across international markets, this becomes even more important. Price floors that hold in one country don't always hold in another, and a violation in one market can bleed into others quickly through gray market activity.
When Scale Makes Manual Monitoring Impossible
The gap between knowing you need better price data and actually having it is usually an infrastructure problem, not a strategy problem.
One global food delivery company faced exactly this. Operating across 28 countries, they needed continuous visibility into competitor pricing, promotions, product availability, and delivery fees, not just for a handful of SKUs, but across entire grocery and quick-commerce catalogs. The markets were different, the competitors were different, and the data needed to be current enough to drive real decisions.
DataHen built and manages the data collection infrastructure behind that operation. Large-scale web scraping pulls granular competitor data from apps and websites across all 28 markets. Custom pipelines deliver clean, structured datasets directly to the client's analytics team on a consistent schedule. A product matching layer ensures that pricing comparisons are always like-for-like, even when competitors name or bundle products differently.
The result is a pricing intelligence operation that would be physically impossible to replicate manually, not because the team isn't capable, but because the volume, frequency, and geographic spread of the data collection is beyond what any manual process can sustain. For a business operating at that scale, clean competitive data arriving on time isn't a nice-to-have. It's how pricing decisions get made.
Is Building Your Own Price Monitoring System Worth It?
The DIY Approach and Why It Stalls
Building your own price monitoring system is technically possible. If you have developers on staff, the initial setup isn't complicated, write some scraping scripts, schedule them to run, pipe the output into a database, build a reporting layer on top. A working prototype can come together in a few days.
The problem isn't the build. It's everything that comes after.
Websites change. Competitor sites update their structure, add JavaScript rendering, introduce bot detection, or shift to single-page application frameworks that break simple scrapers. Every one of those changes requires someone to go back into the code, diagnose what broke, and fix it. That maintenance burden is invisible at the start and substantial six months in.
Then there's scale. A scraper that works on five competitor sites doesn't automatically work on fifty. Handling CAPTCHAs, rotating proxies, managing request rates to avoid blocks, dealing with sites that serve different content to automated visitors, each of these is a solvable problem, but each one adds complexity and maintenance overhead. The engineering time quietly compounds.
I've seen this pattern repeatedly: a team builds a scraping setup that works well for three months, then spends the next six months keeping it alive instead of improving it. The system becomes a maintenance liability rather than a business asset. The data quality degrades, the coverage shrinks, and eventually the team is back to manual checks for the competitors their scrapers can no longer reach.
DIY makes sense in a narrow set of circumstances, a small, stable catalog, a handful of competitors with simple site structures, and a development team with genuine capacity to maintain infrastructure. Outside of that, the hidden costs tend to outweigh the upfront savings.
When to Use a Managed Data Collection Service Instead
A managed data collection service handles the infrastructure so your team doesn't have to. The scrapers, the proxy management, the anti-bot handling, the pipeline maintenance, the data cleaning, all of it runs without your developers touching it. What your team receives is clean, structured, current data. What they don't receive is the operational burden of keeping that data flowing.
The right time to consider this approach is usually one of three moments.
First, when your catalog has grown past the point where manual monitoring is viable but your team doesn't have the engineering bandwidth to build and maintain reliable scraping infrastructure. You need the data now, not after a three-month build cycle.
Second, when data quality has become a real problem. If your current setup, whether manual or a DIY scraper is producing errors, gaps, or stale data that's making it into pricing decisions, the cost of bad data is already higher than the cost of a better solution.
Third, when your monitoring needs span multiple markets, multiple languages, or a large and changing competitor set. Geographic scale and catalog depth are exactly where managed pipelines outperform DIY systems, not because the underlying technology is different, but because the operational complexity of maintaining coverage across dozens of markets is a full-time job that most e-commerce teams aren't staffed to do.
The question worth asking isn't "can we build this?" Most teams can. The question is "what does it cost us to keep it running, and is that the best use of our engineering capacity?" For most growing e-commerce businesses, the answer points toward a managed service, and toward spending that reclaimed time on decisions the data makes possible, rather than the infrastructure that collects it. For more on how competitive pricing strategy fits into that picture, see our ultimate guide to competitive pricing strategies.
Conclusion
Manual price monitoring isn't a flawed strategy, it's a strategy with a hard ceiling. It works until your catalog grows, your competitor set expands, or your market moves faster than a spreadsheet can keep up with. At that point, the cost of staying manual isn't just the hours spent on checks. It's the flash sales you miss, the margin you leave on the table, and the pricing decisions made on data that's already three days old.
Automated competitor price monitoring removes that ceiling. Clean data arrives on a schedule. Coverage spans every competitor, every marketplace, every market you operate in. Your team spends time acting on pricing intelligence rather than collecting it.
The businesses getting this right aren't necessarily bigger or better resourced than yours. They've just stopped treating data collection as something that happens manually, and started treating it as infrastructure, something that runs reliably in the background while the team focuses on decisions.
If your current approach to competitor pricing feels like it's costing you more time than it's giving you insight, that's the signal worth paying attention to.
DataHen builds and manages the data collection pipelines that e-commerce and retail teams use to track competitor prices at scale, across catalogs, markets, and marketplaces. Request a quote to talk through what a clean, automated pricing data feed would look like for your operation.

Frequently Asked Questions
Q: What is competitor price monitoring?
Competitor price monitoring is the process of systematically tracking the prices your competitors charge for the same or similar products across their websites, marketplaces, and other sales channels. It goes beyond checking a price once, it means collecting that data continuously, across your full competitor set, so your pricing decisions are always based on what the market looks like right now rather than what it looked like last week.
Q: How often should you check competitor prices?
It depends on your category and how frequently prices move. For high-competition products on marketplaces like Amazon, prices can shift multiple times per day, hourly monitoring is often warranted. For direct competitor websites with more stable pricing, checking several times daily is usually sufficient. The more important factor is consistency. A reliable automated pipeline running every few hours gives you far more usable data than a manual check that happens whenever someone remembers to do it.
Q: What's the difference between price monitoring and dynamic pricing?
Price monitoring is the data collection side, tracking what competitors charge across products and channels on an ongoing basis. Dynamic pricing is what you do with that data, automatically adjusting your own prices based on rules you define, like matching a competitor's drop or holding your price when a rival goes out of stock. You need the first to do the second well. Dynamic pricing built on stale or incomplete monitoring data tends to react to the wrong signals at the wrong time.
Q: How do you track competitor prices on Amazon and Walmart at the same time?
The short answer is that you need a data collection setup configured to pull from both simultaneously. Amazon and Walmart operate differently, buy box dynamics, third-party seller pricing, and promotional structures vary between them, so the same scraping logic doesn't apply cleanly to both. A well-built price monitoring pipeline handles each source according to its own structure, normalizes the output into a consistent format, and delivers a unified dataset your team can work from. Trying to do this manually across two major marketplaces is where the time cost tends to become unsustainable fastest.
Q: Is manual price monitoring ever good enough?
For a very small catalog, 15 to 20 products, two or three competitors, no marketplace complexity, manual monitoring can cover the basics. The ceiling arrives quickly though. Once your catalog grows, your competitor set expands, or you need data fresher than a daily check can provide, manual methods start producing gaps that affect real decisions. The other limitation is historical data: manual checks give you a point-in-time price, not a pattern. Spotting trends, promotional cycles, or gradual repositioning requires consistent data over time, which spreadsheets rarely produce cleanly enough to analyze.
Q: What data does a competitor price monitoring system actually collect?
More than just a price. A properly configured system captures listed price, sale and promotional pricing, stock availability, delivery fees and free shipping thresholds, buy box status on marketplaces, and in some cases product ratings and review counts. Each of these data points adds context to the headline number. A competitor priced $5 lower than you but charging $9 for shipping isn't actually cheaper, but you'd only know that if your monitoring setup captures delivery costs alongside price.
Q: How do you know which competitors to monitor?
Start with the competitors your customers are actually choosing over you. Cart abandonment data, lost sale patterns, and direct customer feedback are the most reliable sources. If those aren't available, look at who consistently appears in the same search results as your top products, those are the sellers your customers are comparing you against in real time. From there, tier your monitoring: close competitors with overlapping catalogs get high-frequency tracking, peripheral players get checked less often. The goal is coverage where it affects conversion, not exhaustive tracking of every seller in your category.
Q: Can small e-commerce businesses afford price monitoring?
The more useful question is whether they can afford not to. If competitor pricing is affecting your conversion rate, and in most product categories it is, then the cost of missing a competitor's price move shows up in lost sales, not just in your monitoring budget. That said, not every business needs enterprise-grade infrastructure. The right starting point is proportional to your catalog size and competitor complexity. What matters is that the data is reliable and current enough to inform real decisions. A small operation with 50 SKUs and five competitors needs something different from a retailer managing thousands of products across global markets, but both benefit from moving beyond manual checks.
