
Scraping websites can help you get valuable data quickly but often times it is not straightforward. You will most likely run into challenges such as creating requests (you will need to learn how to code and use a library to create http requests which is what browsers make behind the scenes), throttling (a website may only allow a certain number of requests in a certain amount of time to make sure that you don’t bog down their server), and getting your ip banned (sometimes a website will try and prevent you from crawling and ban your ip so you can’t make requests). We are going to show you how using DataHen can handle all these hard parts of scraping and make it simple to get the data you need.
If you prefer to skip this tutorial, you can clone this script directly here.
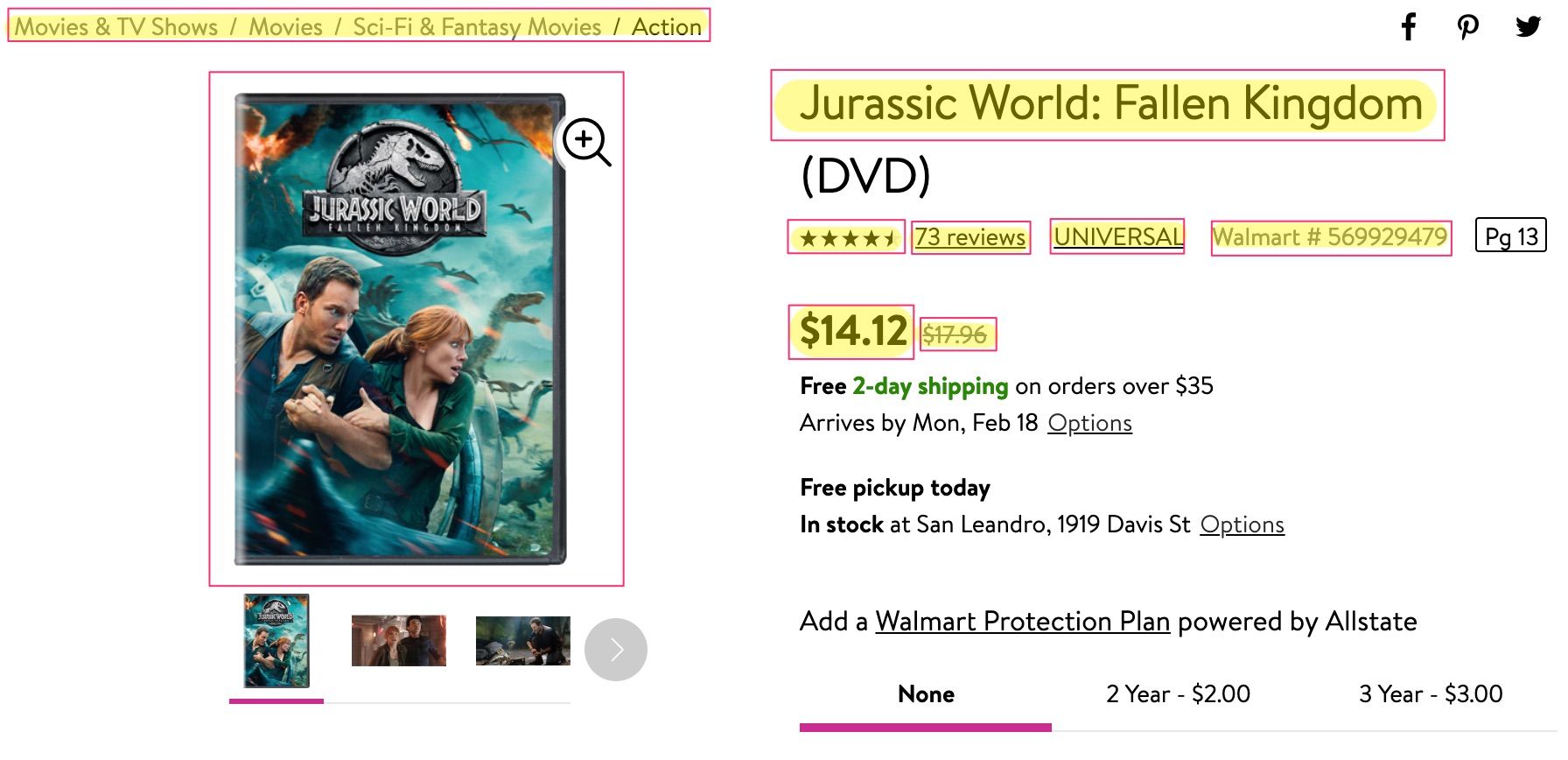
For this tutorial we are going to show you how to use DataHen to easily scrape information about movies (DVDs) on the walmart.com website. Specifically we are going to be extracting the following Walmart dvd data (also highlighted below): title, current price, original price, rating, number of reviews, publisher, Walmart number, image url, and categories.
We are going to assume you have Ruby 2.5.3 and the Nokogiri gem installed. If not follow this link here for instructions on how to install Ruby. Once Ruby is installed, make sure Rubygems is also installed and then run the following to install Nokogiri:
$ gem install nokogiri
First let’s set up a new DataHen scraper. Install the DataHen Ruby gem with the following command:
$ gem install datahen
You should see something similar to the following output after running this command:
Successfully installed datahen-0.2.3
Parsing documentation for datahen-0.2.3
Done installing documentation for datahen after 0 seconds
1 gem installed
Now that we have the DataHen gem installed we need to create our DataHen environment variable token. This will make it so our token is sent with every DataHen request. Run the following command:
$ export DATAHEN_TOKEN=<your_token_Here>
We are now ready to create a scraper. Let’s create an empty directory first, and name it ‘walmart-scraper’:
$ mkdir walmart-scraper
Next let’s go into the directory and initialize it as a Git repository:
$ cd walmart-scraper
$ git init .
Now that you've done the setup, let's move on to the creating the seeders in Part II.
