
Web scraping is a useful skill to have when working with data on the web. In this blog post, we'll demonstrate how to extract information about the largest companies by revenue from a Wikipedia page using Python.
1. Identify the Target Website
First, identify the website you want to scrape. Make sure it contains the data you need and that web scraping is allowed per the site's policies.
For this tutorial, we'll scrape largest company from Wikipedia page:
https://en.wikipedia.org/wiki/List_of_largest_companies_by_revenue
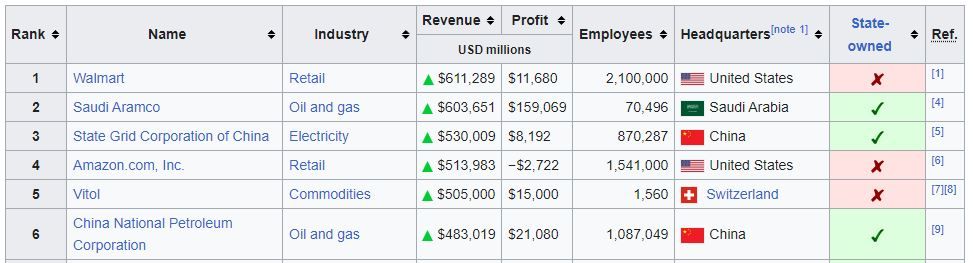
2. Inspect the Page to Find the Data
Use your browser's developer tools to inspect the target page and identify where the data is located. We want to understand the page structure and HTML elements surrounding the data.
To inspect the page HTML, we can right click the cursor and select inspect in the options.
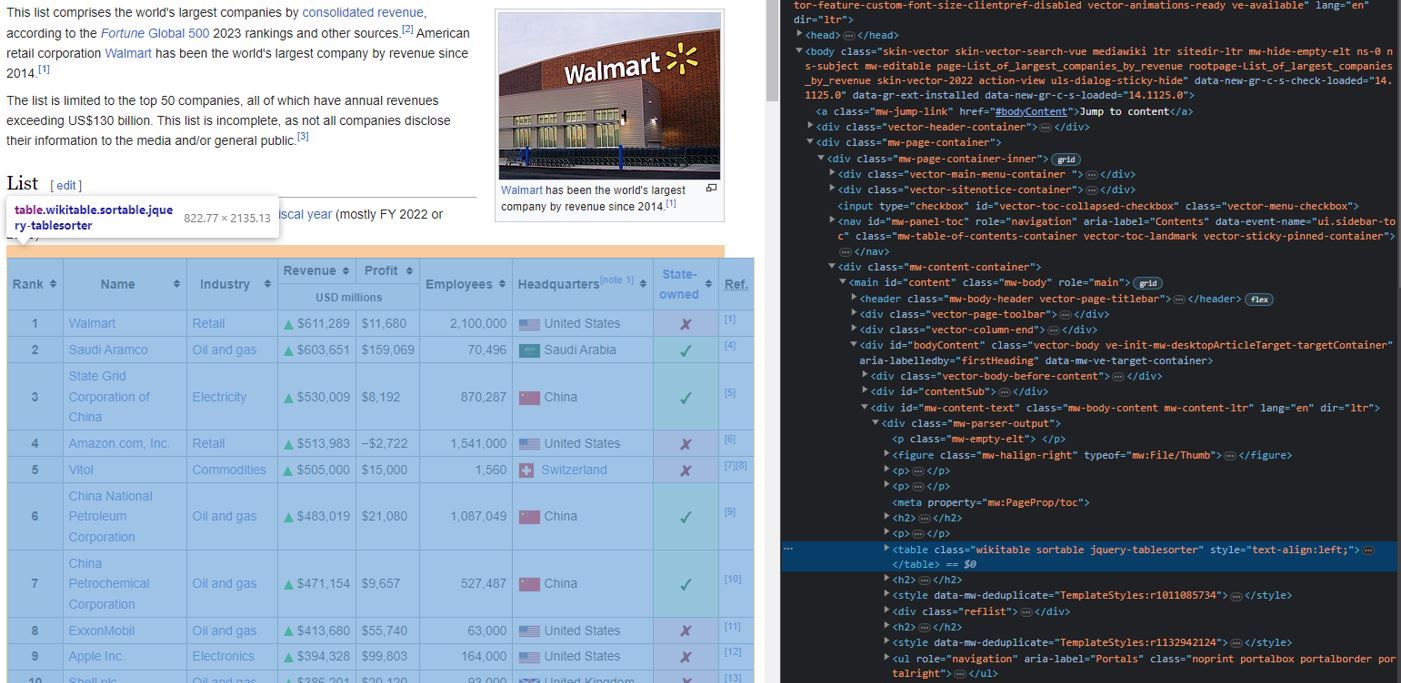
For our target Wikipedia page, the relevant data resides within a <table> element tagged with the class "wikitable sortable jquery-tablesorter". Rows of data are represented with <tr> tags, while individual data points (like company names, revenue figures, etc.) are contained within <td> tags.
3. Write the Scraping Code
Now we can start writing the Python code to scrape the page. The key steps are:
3.1 Importing libraries
We'll import requests for downloading the page, BeautifulSoup for parsing the HTML, and pandas for structuring thescraped data into a table.
import requests
from bs4 import BeautifulSoup
import pandas as pd
3.2 Download page
Use requests.get() to download the page content into a Response object called page. We'll handle any request errors here.
url = 'https://en.wikipedia.org/wiki/List_of_largest_companies_by_revenue'
try:
page = requests.get(url)
except Exception as e:
print('Error downloading page: ',e)
3.3 Parse HTML
Next, we'll parse the page content as HTML using BeautifulSoup so we can extract data from the elements.
soup = BeautifulSoup(page.text, 'html.parser')
3.4 Extract data
Using the elements IDs and classes from inspecting the page, we can now extract the data. We'll locate the rates table, loop through the rows, and extract the text from the code and rate cells.
tables = soup.find_all('table')
dfs = []
for table in tables:
dfs.append(pd.read_html(str(table))[0])
This will print each row from the table.
We use soup.find_all('table'), which finds all <table> tags in the webpage. Tables are often used in HTML to structure tabular data.
The loop then goes through each of these tables, converts them to a string, and uses pd.read_html() to convert the HTML table into a pandas DataFrame. Each resulting DataFrame is appended to the dfs list
4. Extract and Structure the Data
To make the scraped data more usable, we can extract it into a pandas dataframe with labeled columns rather than just printing it.
top_revenue_companies = dfs[0]
top_revenue_companies.columns = top_revenue_companies.columns.get_level_values(0)
top_revenue_companies = top_revenue_companies.drop(columns=["State-owned", "Ref."])
The first line assumes the table of interest is the first one on the page, so it's extracted from the 'dfs' list and stored in 'top_revenue_companies'.
The next line flattens the column headers. Multi-index columns have multiple levels of headers, and 'get_level_values(0)' gets the top-level headers.
The last line drops the columns named "State-owned" and "Ref." as they're not needed in our final dataset.
5. Store and Analyze the Scraped Data
With our data extracted, we can now store it for further analysis. Some options for storage include:
- Save to CSV file
- Insert into database like MySQL
- Export to Excel
- Store in object storage like S3
For example:
top_revenue_companies.to_csv('exchange_rates.csv', index=False)
We will save the dataframe to a CSV file that can be opened in Excel or other tools.
The scraped data can then be used for financial analysis, data visualizations, algorithmic trading, machine learning and more. The key is getting high quality, structured data from the web.
Let's put all the code together:
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://en.wikipedia.org/wiki/List_of_largest_companies_by_revenue'
# https://dmtsms.scotiabank.com/api/rates/fxr
try:
page = requests.get(url)
except Exception as e:
print('Error downloading page: ',e)
soup = BeautifulSoup(page.text, 'html.parser')
# Find all tables in the webpage
tables = soup.find_all('table')
# Iterate over each table and convert to DataFrame
dfs = [] # This will contain all dataframes
for table in tables:
dfs.append(pd.read_html(str(table))[0])
top_revenue_companies = dfs[0]
top_revenue_companies.columns = top_revenue_companies.columns.get_level_values(0)
top_revenue_companies = top_revenue_companies.drop(columns=["State-owned", "Ref."])
top_revenue_companies.to_csv('exchange_rates.csv', index=False)
Running this script will:
- Download the web page containing the exchange rates table
- Parse the HTML from the page
- Find the table and loop through the rows, extracting the currency codes and exchange rates
- Store the scraped data into a pandas dataframe
- Print out and save the dataframe to a CSV file
This gives us a nice, structured dataset collected automatically from the website. We can schedule and run this script on a regular basis to keep the rates data up to date.
Limitations and Risks of Web Scraping
While useful, web scraping also commes with some limitations and risks to be aware of.
- Sites can block scrapers be detecting unusual traffic and access patterns. This can lead to IP bans.
- Heavy scraping can overload target sites, causing performance issues or service disruptions.
- Data formats and page structures may change over time, breaking scrapers. They require maintenance.
- Complex sites relying heavily on JavaScript can be difficult to scarpe compared to static pages.
- Scraped data may contain inconsistencies, error, and inaccuracies from the original site.
- Legal action is possible if scraping copyrighted data or violating a site's terms of service.
- Scraped data may become oudated quickly if the source site's content is rapidly changing.
By understanding these limitations, we can take steps to mitigate risks and scrape responsibly. The quality of the original site greatly impacts the quality of scraped data as well.
Conclusion
This tutorial covers the fundamentals for web scraping, including:
- How to identify target sites and data to scrape
- Techniques for analyzing page structure and formulating scraping logic
- Writing Python code leveraging libraries like Request, BeautifulSoup, and Pandas
- Extracting, structuring, and storing scraped data for further use
- Following best practices for respectful, sustainable web scraping
Scraping opens up many possibilities for gathering valuable data at scale for analytics, machine learning, business intlelligence and more.
Need Expert Web Scraping Services?
If you've found this tutorial helpful, imagine what expert assistance could do for your web scraping needs! At DataHen, we provide top-tier web scraping services tailored for businesses, ensuring you get accurate, high-quality data without the hassle.